背景
問題
- オンプレミスの環境で動いているL7ロードバランサーを冗長化したい
- パブリッククラウドのようなマネージドロードバランサーはない環境
- アプリケーションはKubernetesクラスタやVMを用いて冗長化されているが、LBが単一障害点だった
- 5台のMiniPCによりクラスタを組んでいるが、まれにこのノードが突然死する場合があり、その際にLBが巻き込まれるという事象が起きた
- ここのサーバーでは自前運用のmisskeyのサーバーが動いており、ActivityPubで外部のサーバーと通信している
- ActivityPubの接続は善意でなりたっているため、長いこと応答をしない場合ActivityPubの配送をストップされることがある
- ActivityPubの再送処理により連合サーバーがリトライをし続けリソースを消費させてしまう
- ここのサーバーでは自前運用のmisskeyのサーバーが動いており、ActivityPubで外部のサーバーと通信している
アプローチ
- これらの問題を解決するために、
VRRPというプロトコルとkeepalivedというソフトウェアを用いる - VRRPはRFCとして標準化されている
- マルチキャストで一定間隔で通信を行い、現在のMasterのダウンを検出した場合、次にpriorityが高いノードがMasterのIPアドレスを引き継ぐことで冗長化を実現する
用語
virtual address: 冗長化を行うIPアドレス
概要
| Linux distribution | Ubuntu 22.04.2 LTS |
| keepalived | Keepalived v2.2.4 (08/21,2021) |
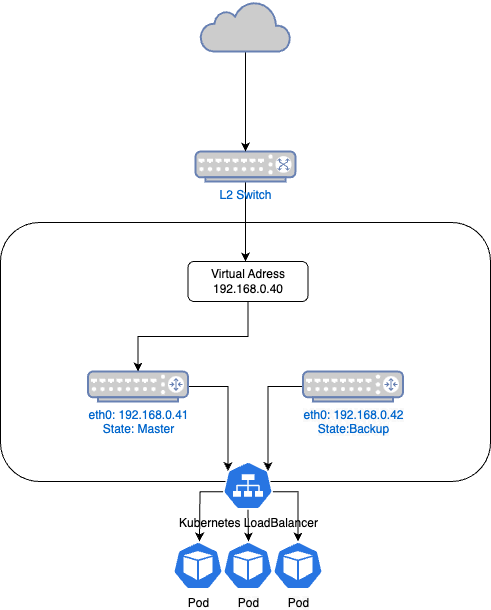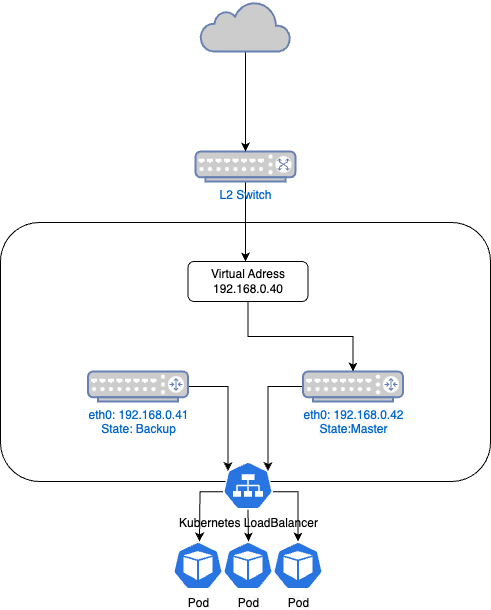
※本来はProxmoxのクラスタや複数のスイッチなどもあるが、簡単のため割愛
本構成ではルーターが443ポートを転送する先の冗長化を行う virtual address が 192.168.0.40
192.168.0.40 の冗長化を受け持つサーバーのIPアドレスが 192.168.0.41, 192.168.0.42 という構成
192.168.0.41, 192.168.0.42には Caddy のProxyサーバーが動いており、HTTPSの終端とReverse Proxyを行い、ホスト名に応じてKubernetesのロードバランサーや他のVMに振り分けを行う。
設定
keepalived のインストール
sudo apt install keepalived
192.168.0.41の設定
global_defs {
vrrp_garp_master_refresh 60
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass password
}
virtual_ipaddress {
192.168.0.40
}
}
192.168.0.42の設定
global_defs {
vrrp_garp_master_refresh 60
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass password
}
virtual_ipaddress {
192.168.0.40
}
}
192.168.0.41 のMaster Serverとの差分は state, priority のみ
設定値の解説
vrrp_garp_master_refresh: Master が gratuitous ARP を送りARPテーブルを更新させる間隔(秒)
state: 該当ノードが初期に担当する役割
priority: ノードの優先度(Master > Backup)
virtual_router_id: ルータの識別ID
advert_int: VRRPのアドバタイズ通信の送信間隔(秒)
フェイルオーバーの確認
192.168.0.41のターミナル
bootjp@vrrp-lb01:~$ ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 7e:6b:e5:4e:f4:ce brd ff:ff:ff:ff:ff:ff
inet 192.168.0.41/24 brd 192.168.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.40/32 scope global eth0
valid_lft forever preferred_lft forever
192.168.0.41 のほかに virtual address である 192.168.0.40 が付与されていることが確認できる
192.168.0.42のターミナル
bootjp@vrrp-lb02:~$ ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 02:00:50:01:ba:9c brd ff:ff:ff:ff:ff:ff
inet 192.168.0.42/24 brd 192.168.0.255 scope global eth0
valid_lft forever preferred_lft forever
192.168.0.42 のipアドレスのみがついていることが確認できる
実際にフェイルオーバーの動作確認をする
192.168.0.41のターミナル
bootjp@vrrp-lb01:~$ sudo systemctl stop keepalived.service bootjp@vrrp-lb01:~$
192.168.0.42のターミナル
bootjp@vrrp-lb02:~$ ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 02:00:50:01:ba:9c brd ff:ff:ff:ff:ff:ff
inet 192.168.0.42/24 brd 192.168.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.40/32 scope global eth0
valid_lft forever preferred_lft forever
bootjp@vrrp-lb02:~$ journalctl -f -u keepalived.service
Jul 24 12:42:12 vrrp-lb02 Keepalived_vrrp[648]: (VI_1) Entering BACKUP STATE
Jul 24 12:47:23 vrrp-lb02 Keepalived_vrrp[648]: (VI_1) Entering MASTER STATE
192.168.0.42 を持つノードに 192.168.0.40 が付与されていていることが確認できた。
他に検討をした構成
- ECMP(Equal Cost Multi Path) を用いたロードバランシング
- BGPを用いてネットワークを運用している環境であればおそらく採用していた
- VMのHA構成によるマイグレーション
- 実は当初この構成で運用を行っていた。
- Proxmoxのクラスタ構成を用いた HA 構成によりフェイルオーバー
- 実際に特定のノードがクラッシュした際に正しくフェイルオーバーは動作していた
- とはいえ、ノードの外にストレージを配置する必要があるため、外部のNasにVMのデータが依存し、Nasのメンテナンスを困難にするため今回の構成に移行した
- ノードのストレージを使ったCephクラスタがあれば、この構成でよかったかも
- すべてLVMに割り当てをしてしまったため、Cepth用にノードのディスクを再構成する予定